成为开发者:MiniKV Web
下载Epub格式电子书->成为开发者:MiniKV Web
成为开发者:MiniKV Web
前言:从零开始,写出你的第一个完整软件
你好,我是DNG,一个不擅长写作和录制视频的人,但是我总想写一些什么,所以今天我将会演示开发的大致流程,欢迎来到程序员的世界,你可以随意修改这个markdown文件,写下你的笔记。
这不是一段高深莫测的计算机科学研究,也不是一场花哨的炫技展示,而是一次非常朴素的实践——我们要从零构建一个“真正能跑”的数据库系统,一个带前端、能通过浏览器访问的简化版 Web 服务。
这本小册子的目标是带你亲手完成一个有“全套流程”的项目。不只是写几行 Hello World,也不只是学点 C 语言语法,而是完整体验一次从无到有的软件开发之旅:从代码到网页、从存储到接口、从命令行到浏览器。
为什么需要这个项目?
如果你是计算机专业的新生,你可能有这样的困惑:
- 编程到底是干嘛的?为什么老师让我们学操作系统、学编译原理,可是我一点也没感受到它们和“开发”有什么关系。
- 为什么我做了很多实验、写了很多代码,但却不知道“开发一个产品”是什么样?
- 我能不能自己写一个真正有用的软件?
这些问题我也曾有过。在刚学计算机那几年,我学了很多工具、很多语言、很多“知识点”,但却始终搞不懂一件事:我究竟什么时候才是在“做开发”?
直到我开始写自己的东西,写那种“从头开始,最后能运行”的项目,我才真正理解,开发不仅是写代码,更是设计一个系统、解决一个问题、把抽象的想法变成现实的过程。
MiniKV Web 就是这样一个项目。它虽然小,但麻雀虽小,五脏俱全。它拥有:
- 一个数据库引擎,支持 SQL 子集(
CREATE/INSERT/SELECT); - 一个Web 服务,用最原始的 C 语言 socket 实现 HTTP;
- 一个前端页面,用 HTML 和 JS 让你直接在浏览器输入 SQL 查询;
- 一个调试工具链,使用 gdb 追踪错误、Check 进行单元测试;
- 一个容器化环境,使用 Docker 快速部署运行;
- 一个构建系统,使用 CMake 管理依赖与构建逻辑。
这些都是现代开发者每天都在做的事,只不过我们把它简化、拆解、讲清楚,让你第一次真正理解它们在一起是怎么工作的。
你将学到什么?
这不是一套“让你变成全栈工程师”的花哨教程,也不是那种“短期速成,快速就业”的课程。我们要做的,是一件更重要的事情:
让你真正理解开发的本质,并有能力从零构建一个小而完整的系统。
我们会一起动手完成:
- 从零写一个数据库引擎:不使用 SQLite、不使用任何框架,直接从
parser -> engine -> storage的架构入手,让你第一次明白数据库是如何理解一条 SQL 并存入数据的。 - 实现一个 HTTP 服务:不是用 nginx,不是用 Flask,而是用纯 C 实现 TCP socket 监听,手动处理 HTTP 请求报文。
- 开发一个 API 层:把 SQL 执行封装成 RESTful API,让后端与前端对接。
- 写一个前端页面:用 HTML+JS 构建一个简单界面,实现数据交互和展示结果。
- 测试与调试:用 Check 写单元测试,用 gdb 追踪 HTTP 请求的执行路径。
- 部署与发布:用 Docker 打包环境,让别人可以一键运行你的作品。
你不需要之前学过这些内容,我们会一点点解释每一个工具、每一个模块、每一个设计决策——让你既能“用”,又能“懂”。
为什么选 C 语言?
我知道你可能更熟悉 Python、Java,甚至是 Rust。但我们这次选择了 C。
为什么?不只是因为教学视频需要一个大部分人都能看懂的编程语言,还因为 C 能让你看见计算机的本质。在 C 里,没有 ORM、没有框架、没有高层抽象,一切都非常原始——你要自己处理内存、你要亲手写 socket、你要控制数据在内存中的布局。
听起来困难,但正是这种“低级”的体验,才让你真正理解计算机运行的逻辑。当你用 C 写完一整套系统之后,再回头看 Python 或 Java,你会豁然开朗。
你会明白:开发不只是写语法对的代码,更是设计结构、理解系统、思考接口的过程。
项目概述
MiniKV Web 是一个轻量级的键值数据库引擎,使用 C 语言开发,并通过内置 HTTP 服务提供 RESTful 接口,支持浏览器前端访问。数据库内核设计与 Web API 集成的最小实现,作为教学示例和个人开发流程的入门。
项目结构
.
├── CMakeLists.txt
├── docker
│ └── Dockerfile
├── include
│ ├── api_handler.h
│ ├── engine.h
│ ├── http_server.h
│ ├── parser.h
│ └── storage.h
├── src
│ ├── api_handler.c
│ ├── engine.c
│ ├── http_server.c
│ ├── main.c
│ ├── parser.c
│ └── storage.c
├── test
│ ├── test_engine.c
│ ├── test_parser.c
│ └── test_storage.c
└── web
├── app.js
├── index.html
└── style.css技术选型
| 组件类型 | 技术选型 | 备注 |
|---|---|---|
| 编程语言 | C语言(核心模块 + HTTP 服务) | 大部分都学过C |
| 操作系统 | Debian GNU/Linux | 稳定好用 |
| IDE | LazyVim(Neovim增强发行版) | 本次只用NeoVim |
| 构建工具 | CMake | C绑定的 |
| 版本控制 | Git | 最重要 |
| 容器化部署 | Docker | 部署用 |
| 单元测试 | Check | |
| 调试工具 | gdb | |
| 前端页面 | HTML + JavaScript(静态资源) | 没得选 |
| 通信协议 | HTTP/1.0 + REST API | 没得选 |
功能说明
- 数据库内核:简化的关系型存储,支持 SQL 子集(如
CREATE/INSERT/SELECT)。 - HTTP Server:纯 C 实现的基础 HTTP 服务,内嵌 REST API 接口。
- 前端交互:通过静态 HTML 页面与 JS 脚本实现可视化的 SQL 请求与结果显示。
- 跨平台运行:可在主机或 Docker 容器中编译运行,部署方便。
- 开发友好:集成现代开发工具链,支持测试、调试、构建一体化流程。
开发过程速览:
第一步:准备环境
- 你需要的工具不多,只要一台安装了 Debian 系统的电脑,或者任意 Linux 环境也可以。安装好以下工具:
git(版本控制)cmake(构建工具)build-essential(C 工具包)check(用于测试)gdb(调试器)curl(命令行接口测试工具)
- 配置 Git 统一提交风格
第二步:开发数据库内核
我们实现了一个轻量级数据库 MiniKV 的结构,目标是让它支持基本 SQL 操作,比如:
SET Key Value:将Key设置为ValueGET key:获取Key的值
数据流大致是: SQL 字符串 → 解析器(parser)→ 执行引擎(engine)→ 内存存储结构(storage)
先实现这个“从字符串到结果”的过程,再往里面加功能。
第三步:实现内置 HTTP Server(http_server.c)
接下来,我们要让数据库能接受网页发来的请求。于是写了一个很简单的 HTTP/1.0 服务程序,叫做 http_server.c。主要功能:
- 监听端口(用 socket)
- 等待请求
- 识别请求内容,返回结果
重点支持一个 POST 接口:
POST /api/query:接收 SQL 字符串,执行后返回查询结果(我们用字符串拼 JSON,避免引入第三方库)
第四步:API处理层(api_handler.c)
HTTP 请求收到了,接下来就交给 api_handler.c 来做实际工作:
- 解析 URL 和请求体里的 SQL
- 调用我们之前写的
parser.c来执行 SQL - 把结果整理成 JSON 字符串,返回给客户端
这个模块负责“翻译前端请求 → 调用后端逻辑 → 返回数据”。
第五步:构建前端页面
我们写了一个非常简洁的前端界面,包括:
index.html:输入框和一个“执行”按钮app.js:用fetch('/api/query')发起 POST 请求,把用户输入的 SQL 发过去,收到结果后显示在网页上- sytle.css 我个人审美的页面
这样用户就可以在网页里输入 GET Key,直接看到查询结果。
第六步:测试与调试
开发完成后,我们需要确保它是“能用的”,甚至在错误输入时也能稳定运行。我们做了几个方面的测试:
- 用
Check写了测试代码来验证数据库查询是否正确 - 用
curl模拟 POST 请求,测试 API 是否响应正常 - 用
gdb调试关键路径,比如断点跟踪 SQL 是怎么一步步被执行的
第七步:部署与发布
整个系统支持使用 Docker 一键部署。只需写好 Dockerfile,包括:
- 安装依赖
- 编译程序
- 启动 HTTP 服务
然后运行:
docker run -p 8080:8080 minikv-dev浏览器打开 http://localhost:8080,就能看到你的网页了!
(可选) 提升开发体验的小技巧
本次开发用的是 Neovim,你可以看我之前翻译的书,《给雄心勃勃的开发者的LazyVim指南》尝试 LazyVim 插件配置,配合以下工具:
clangd:支持代码智能跳转cmake-tools.nvim:一键构建nvim-dap+gdb:支持调试前端发来的 SQL 请求
第一章:准备开发环境
在开始编码之前,我们先为项目构建一个统一、稳定的开发环境。本章将介绍如何通过虚拟机安装 Linux 系统(选用 Debian),以获得一致的编译、调试与运行体验。
1.1 安装虚拟机软件
为了统一环境,我们使用虚拟机,虚拟机软件就两个可以选,VirtualBox 开源、轻量化。VMware 企业级应用,资源占用较大、功能更复杂
官网在这里:VirtualBox
Download然后一键安装就行。
1.2 安装Debian操作系统
本书选择 Debian GNU/Linux 作为开发操作系统只有一个原因:
Debian稳定:每个稳定版本的更新周期长达数年,适合构建长期项目。
关于我选择 Debian 的理由,也可阅读:->Debian:我的长期选择
官网下载页面指路->Debian
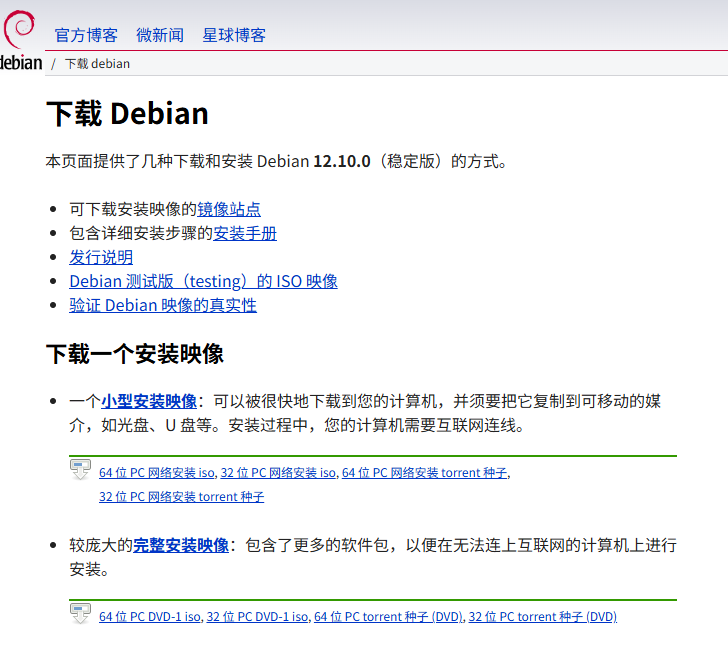
最好选择完整安装映像下的 64 位 PC DVD-1 iso 。
下载慢怎么办?兰州大学的镜像站->Index of /debian-cd/12.10.0/amd64/iso-dvd/ | 兰州大学开源社区镜像站

然后打开Vmbox软件,选择新建
起名,选择虚拟光盘,选中跳过自动安装。
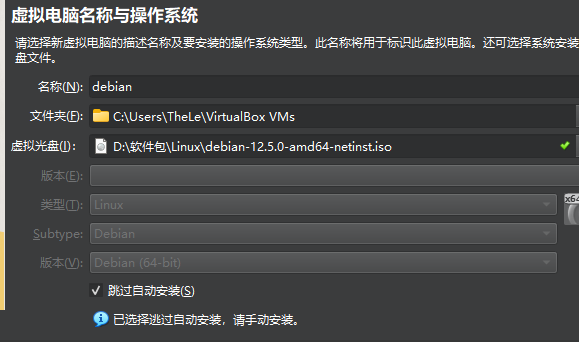
推荐配置 4096GB内存+ 4核 + 60GB存储,丰简由人。
然后启动Debian!
图形化安装,我提一些重要的,实在担心你就看我的视频。
直接回车第一个Graph安装
语言选择汉语,地区选中国。
root密码,域名,用户名,用户密码。我全设置的是debian,为了方便。
硬盘分许选择/home放在单独一个分区,或者新手推荐的一整块分区都行。
使用网络镜像站点选择是,然后选tuna。

软件选择:Gnome+web+SSH+标注系统工具就行
1.3 基础环境配置
授予debian用户管理员权限
Debian 系统默认不会赋予新建用户管理员权限,尤其在最小化安装时。通过将用户 debian 添加到 sudo 用户组,可以赋予其“按需提权”能力,使其可以执行需要 root 权限的命令,如系统安装、配置修改等。这个操作本质上是将该用户加入 /etc/group 文件中 sudo 所对应的行,实现组成员授权。
权限控制是Linux作为多用户操作系统的核心功能。
将用户 debian 添加到 sudo 组,以便其具备使用 sudo 命令的权限。
-
以 root 权限打开
/etc/group文件:sudo nano /etc/group -
找到包含
sudo的那一行(大致如下):sudo:x:27: -
将用户名
debian添加到该行末尾:sudo:x:27:debian如果已有其他用户,格式如下:
sudo:x:27:alice,debian -
保存并退出(在
nano中按下Ctrl+O保存,Ctrl+X退出)。
验证是否添加成功
通过以下命令验证是否已经添加成功:
groups debian如果看到 sudo 出现在输出中,表示已成功添加:
debian : debian sudo设置软件源
使用完整DVD 安装版的Debian时,系统会默认将光盘作为软件源,并在 /etc/apt/sources.list 文件中设置了 cdrom: 开头的源,而没有启用网络的软件源。
因此执行 apt update 时,系统尝试从光驱读取软件包索引,导致报错,提示需要插入 DVD 或使用 apt-cdrom。
方案 A(命令行):手动编辑 /etc/apt/sources.list 文件,注释掉 cdrom: 行,并添加可信的网络源,例如清华大学的 Debian 镜像。
sudo nano /etc/apt/sources.list
# deb cdrom:[Debian GNU/Linux 12.0.0 _Bookworm_ - Official amd64 DVD Binary-1 20230610-10:42]/ bookworm main
# 清华大学 Debian 源 - Bookworm
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security bookworm-security main contrib non-free non-free-firmware方案 B(图形化):通过“软件与更新”图形工具界面勾选所需的组件,并移除 cdrom: 类型的软件源。
打开软件与更新
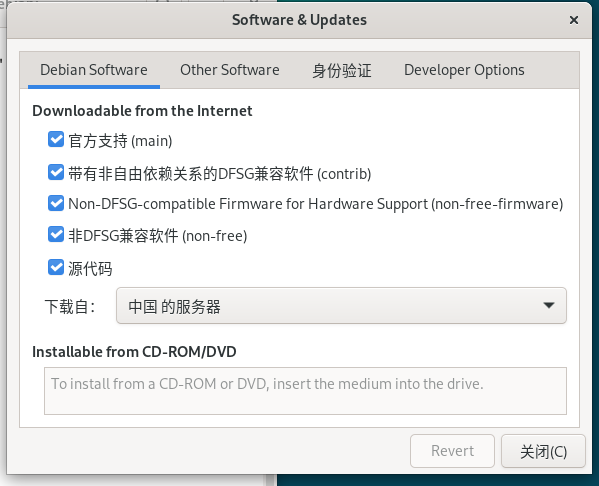
Debian Software页面都选上,然后选择中国的服务器。
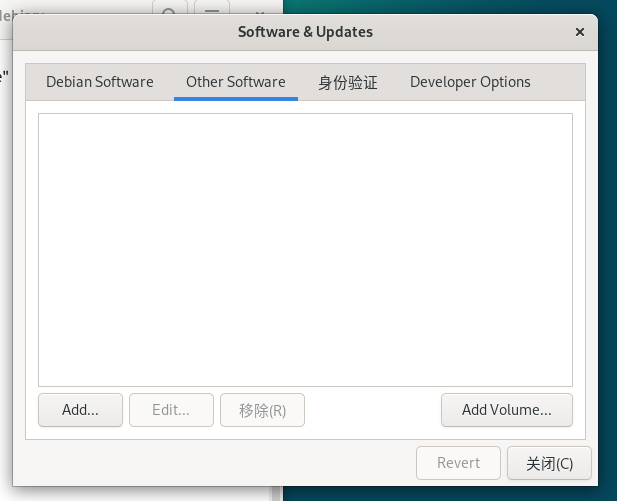
Other Software移除cdrom
设置网络代理
为了让虚拟机访问宿主机提供的代理服务(如 Clash、v2ray、Privoxy 等),需要将虚拟机的网络模式设置为“桥接模式”,从而让其成为局域网中与主机平等的独立节点。设置完成后,虚拟机可以直接通过主机的 IP 和端口访问本地运行的代理服务。
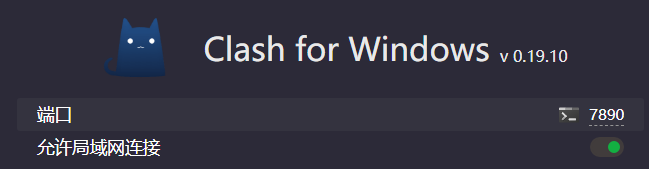
务必确保代理工具允许来自局域网的访问(如 Clash 的 allow-lan: true 设置)。
控制->设置->网络 调成桥接网卡
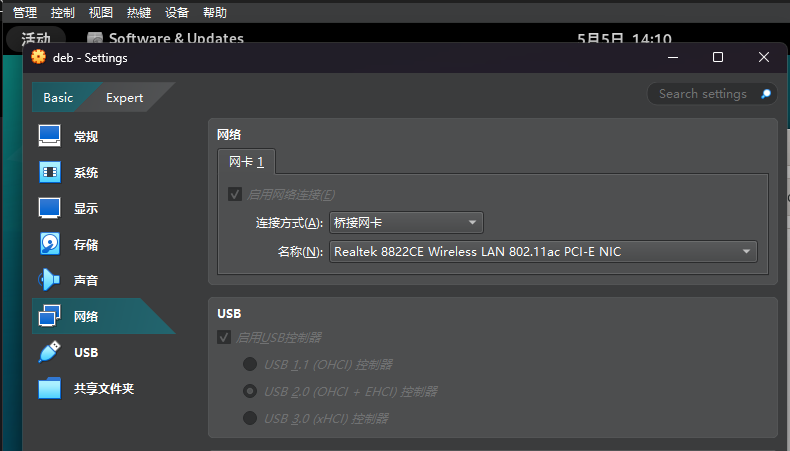
重启虚拟机,网络设置里面设置代理,主机需要开机允许局域网链接的代理服务,虚拟机中填写主机ip:端口。
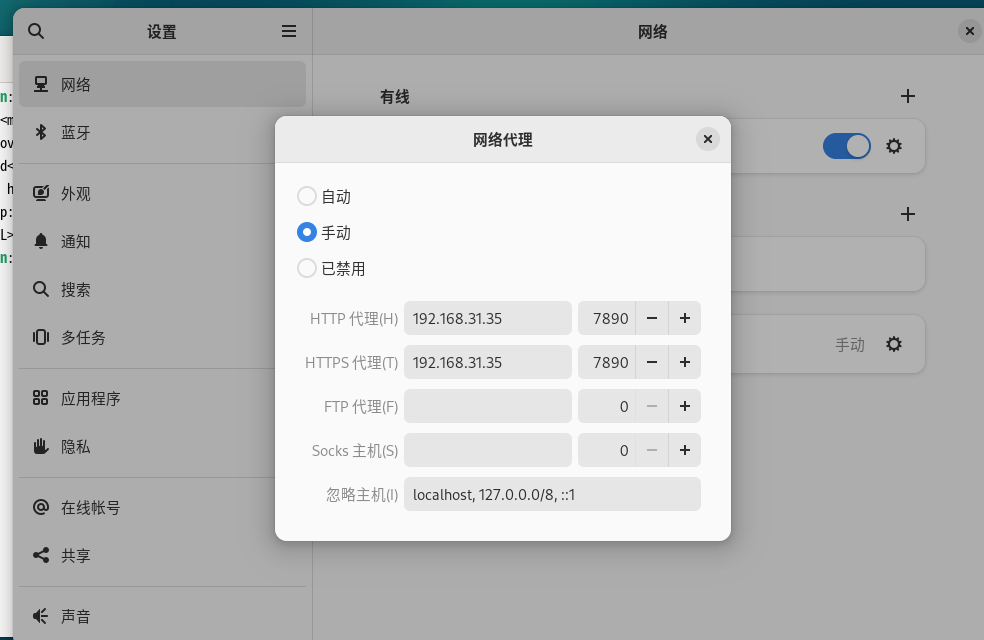
关于网络代理,你可以用Google镜像站点搜索“平价机场”去购买服务,月付不超过20元都是合理的。
快照
快照(Snapshot)是虚拟机提供的一种“系统状态冻结”功能,能够在任意时刻保存当前操作系统的完整运行状态,包括磁盘内容、内存状态、CPU 寄存器及设备连接等。在 VirtualBox 中创建一个时间点,一旦未来系统出现问题,可一键回滚。
控制->设置->生成快照
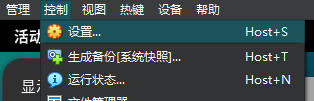
以备不时之需。
1.4 安装开发工具!
终端输入:
sudo apt update
sudo apt install -y \
git \
cmake \
clang \
check \
gdb \
curl \
build-essential \
pkg-config先来解释一下都做了什么
sudo apt update
更新 APT 本地的包索引缓存,确保获取的是最新的包版本。
apt install -y …`
无交互方式安装以下列出的软件包,-y 表示自动回答“yes”跳过确认。
那么我们都一口气安装了什么工具呢?
| 包名 | 作用 | 常见用途 |
|---|---|---|
git |
分布式版本控制工具 | 克隆仓库、管理代码版本 |
cmake |
构建自动化工具,生成 Makefile 或 Ninja | 跨平台构建系统,用于配置 C/C++ 项目 |
clang |
LLVM 提供的 C/C++/Objective-C 编译器 | 替代 GCC,强调模块化、诊断优秀 |
check |
C 语言单元测试框架 | 编写 C 单元测试代码,提供断言和测试报告 |
gdb |
GNU 调试器 | 调试 C/C++ 程序,如设置断点、单步执行 |
curl |
命令行 HTTP 客户端 | 下载文件、测试接口、API 调用 |
build-essential |
编译工具合集(含 gcc、g++、make 等) | C/C++ 开发环境的核心包 |
pkg-config |
查询编译时所需的库和参数 | 自动获取 .pc 文件中指定的 -I、-l 参数 |
ca-certificates |
SSL 根证书 | 确保 curl、git 等工具能正常进行 HTTPS 通信 |
1.5 Linux的重要理念
Linux有很多要学习,我在这里只传达几个重要的理念,和标注出可能会用的命令。
- 一切皆文件
无论是硬盘、网络、终端、设备,Linux 都以“文件”方式暴露出来。 读文件 -> 操作设备;写文件 -> 控制网络;标准输入输出 -> 就是文件描述符。
cat /proc/cpuinfo # 查看CPU信息(本质是个文件)
ls /dev/tty* # 所有终端也是设备文件- 用小工具组合构建大系统
不要造轮子,善用 | 管道、重定向、组合命令。Linux 鼓励用小程序“串起来”。
cat access.log | grep 404 | wc -l # 查找所有 404 错误并统计数量- 自动化优于手动操作
Shell 是系统接口,不是临时敲命令的地方。重复的命令一定写脚本、一定重定向日志、一定写 Makefile。
#!/bin/bash
make && ./test && echo "测试通过"- 默认非 root,默认无权限
默认安全、默认最小权限。不用 root 权限运行服务、不随意 chmod 777、不共享宿主资源。
sudo adduser devuser # 创建干净的开发用户
chown devuser:devuser # 赋予目录权限- 可解释、可替换、可构建
Linux 一切都鼓励透明操作。配置是文本、依赖是包、结果是二进制、构建是自动化。
less /etc/ssh/sshd_config # 所有服务配置都可查看、可编辑1.6 Linux常用命令
文件与目录操作
| 命令 | 用途 |
|---|---|
ls -al |
列出所有文件(含隐藏)+ 权限 |
cd /path/to/dir |
切换目录 |
cp a.txt b.txt |
复制文件 |
mv a.txt dir/ |
移动/重命名 |
rm -rf dir/ |
强制删除目录(危险) |
tree |
树状显示目录结构(需安装) |
用户权限管理
| 命令 | 用途 |
|---|---|
whoami |
当前用户 |
sudo |
提权执行 |
chmod +x file.sh |
赋可执行权限 |
chown user:group file |
修改属主属组 |
groups |
当前用户组列表 |
软件安装与管理(Debian/Ubuntu)
| 命令 | 用途 |
|---|---|
sudo apt update && sudo apt upgrade |
更新软件源 |
sudo apt install cmake git gdb |
安装常用工具 |
dpkg -l |
查看所有已安装包 |
which gcc |
查找程序路径 |
进程与内存查看
| 命令 | 用途 |
|---|---|
ps aux |
grep myprog` |
top / htop |
实时资源占用 |
kill -9 PID |
强制杀进程 |
free -h |
内存状态 |
网络相关
| 命令 | 用途 |
|---|---|
curl -X POST http://localhost:8080 |
模拟接口请求 |
ss -tuln |
查看端口监听状态 |
ping 8.8.8.8 |
测试网络连通性 |
ifconfig / ip a |
查看网络 IP |
查找与分析
| 命令 | 用途 |
|---|---|
grep "main" |
在文件中查找文本 |
find . -name "*.c" |
查找所有 .c 文件 |
du -sh * |
查看当前目录占用 |
df -h |
查看磁盘挂载和使用情况 |
第二章:开发数据库内核
2.1 什么是 Key-Value 数据库?
Key-Value 数据库(简称 KV 数据库),是最简单也是最常见的一类数据库模型。它以 键(Key)与值(Value)成对 的形式存储数据,就像一个巨大的哈希表:
"user:1001" => { "name": "Alice", "age": 23 }
"config:max_conn" => "1024"你可以把它理解为“放大版的字典”——键是唯一的索引,值可以是字符串、二进制数据或结构化 JSON。
KV 数据库的核心特性:
- 极快的读写性能(O(1) 或 O(log n))
- 数据模型简单、灵活
- 适合缓存系统、配置中心、用户会话等场景
常见的代表:Redis、RocksDB、LevelDB、TiKV 等。
2.2 它与传统数据库有什么不同?
| 特性 | Key-Value 数据库 | 关系型数据库 |
|---|---|---|
| 数据结构 | 键值对 | 表、行、列 |
| 查询方式 | 基于键 | SQL(支持复杂查询) |
| 架构设计 | 简单 | 丰富(事务、索引、视图) |
| 使用场景 | 缓存、配置、分布式存储 | OLTP、报表系统 |
KV 数据库往往作为“性能优先”的系统使用,重吞吐、轻事务、不支持复杂联表查询。
2.3 KV 数据库的底层数据结构有哪些?
一个优秀的 KV 系统,底层数据结构必须支持:
- 快速插入和查找(对 key 高效)
- 有序或非有序键空间
- 支持持久化写入或基于内存优化
我们按“存储模型”分两大类进行说明:
一、基于内存的数据结构(如 Redis)
- 哈希表(Hash Table)
- 插入、查找时间复杂度近似 O(1)
- 不支持有序遍历
- 冲突处理通常使用链地址法或开放地址法
- 跳表(Skip List)
- Redis 默认用它作为有序集合底层
- 支持范围查询和有序遍历
- 插入、查找 O(log n)
- 压缩列表(Ziplist)
- 节省内存,但查询性能一般
- 适合值很短、元素很少的场景
二、基于磁盘的数据结构(如 RocksDB)
- B+ Tree
- 传统关系型数据库的主力
- 支持范围查询、有序遍历
- 更适合磁盘(页式存储)
- LSM Tree(Log-Structured Merge Tree)
- 写性能极强(顺序写 + 延迟合并)
- 使用 WAL(Write Ahead Log)保证持久性
- 查询需要合并多个层级,需用 Bloom Filter 加速
2.4 MiniKV 内核为何选择哈希表作为起点?
MiniKV 是一个轻量、教学向的项目,它的目标是:
- 优先理解核心执行路径(parser → engine → storage)
- 关注数据结构在内存中的行为
- 避免引入复杂的文件格式与事务管理
因此:
-
第一阶段 采用自实现的哈希表存储 key-value 对
支持最基本的插入、查找
-
暂不实现持久化与索引优化(留给你写的)
⚠️提示:MiniKV 后续版本可以尝试替换为 Skip List 或 B+ Tree,并加入持久化模块,作为渐进式优化路径。
2.5 C语言知识回顾
先来简单梳理一下C基础知识,会的不用看了。
基本语法、内存管理、字符串处理和结构体使用。
| 主题 | 内容说明 |
|---|---|
| 变量与类型 | int、char、float、double、指针 |
| 控制结构 | if、switch、for、while |
| 函数定义与调用 | 参数传值、指针传参、返回值 |
| 指针与数组 | 指针运算、数组与字符串、char *argv[] |
| 结构体 | struct 定义、指针访问、嵌套结构 |
| 内存管理 | malloc / free、内存泄漏与检查 |
| 字符串函数 | strcpy / strncpy、strcmp、strlen、sscanf |
| 头文件与声明 | #include、头文件保护、extern 用法 |
C 是静态类型语言,其设计目的之一是为了在编译阶段就建立程序对内存的控制,你声明一个 int,实质上就是向编译器申请一个 4 字节(或平台相关)的连续空间,并指定其语义为整数。
结构体(struct)是 C 提供的最接近“对象”的手段。虽然它不支持封装与继承,但你可以通过嵌套与函数指针模拟出“方法”与“行为接口”的组合。在 MiniKV 中,我们大量使用结构体来:
- 定义数据实体
- 在模块边界上传递上下文数据
- 对外暴露统一的数据接口并隐藏细节
结构体指针的使用配合 malloc 形成动态内存数据对象,它的生命周期完全由开发者掌控。
头文件 .h 是模块的“契约”,定义外部可见接口;
源文件 .c 是实现,隐藏细节。合理组织头文件可以达到:
2.6 为什么要模块化设计呢?
因为软件开发是一个团队项目,很多人合作。所以我们要组织多文件项目、分层设计、封装与接口声明,解决这些问题的实践之一就是面向接口编程。
面向接口编程的核心原则是:上层模块不依赖具体实现类,而依赖接口;底层模块实现这个接口。
只关心行为,不关心具体怎么做,这意味着多人协作时,接口定义先行,不同模块可并行开发,而且只要接口不变,随时可以改变你的实现。
模块组织涉及的概念:
.h文件:接口声明(函数签名、结构体定义).c文件:实现逻辑main.c:程序入口,只包含调度逻辑- 模块划分:Parser / Engine / Storage 三层
划分模块的过程可以称之为解耦,削弱相互的联系。
举个例子:
假设我写了一个键值存储系统,暴露了这个 API:
int kv_put(const char* key, const char* value);
char* kv_get(const char* key);你调用这两个函数即可读写数据,但无需知道我底层用了哈希表、B+树,还是黑魔法。
2.7 构建系统与项目管理
使用 CMake 组织构建过程,管理依赖、生成 Makefile。
先简单教学一下,从一个最小可运行的项目出发:
目录结构:
minikv/
├── CMakeLists.txt
├── main.c
└── kv.cCMakeLists.txt 示例:
cmake_minimum_required(VERSION 3.10)
project(minikv C)
add_executable(minikv main.c kv.c)这段定义中有三部分含义:
cmake_minimum_required:指定 CMake 最低版本要求(推荐 3.10+)project(minikv C):定义项目名及语言类型add_executable(...):定义一个可执行目标,并指定其源文件
构建流程如下:
mkdir build && cd build
cmake .. # 生成 Makefile
make # 编译生成 minikv 可执行文件执行成功后,你会在 build/ 下获得可运行的 minikv 程序。
我们还会用到以下语法:
| 内容 | 说明 |
|---|---|
CMakeLists.txt |
描述编译目标、依赖关系 |
add_library() / add_executable() |
添加模块与主程序 |
target_include_directories() |
头文件路径管理 |
target_link_libraries() |
链接测试框架或库 |
2.8 策略模式与接口设计
这是扩展内容,可以在完成项目之后回来看看:
你需要实现可插拔的“存储引擎”(内存/文件/mmap等),学习接口与抽象技巧。
做三件事情:
- 定义抽象
Storage接口(函数指针 + 虚拟表) - 多态实现(使用函数指针替代类方法)
- 结构体 + 函数指针组合(手动实现“面向对象”)
2.9 开发阶段目标
- 实现支持
SET key value与GET key的 KV 数据库。 - 使用接口设计 + 策略模式(可拓展如内存 / 文件 / mmap 存储)。
- 支持 CMock / Check 框架单元测试。
- 使用 CMake 管理整个构建流程。
MiniKV/
├── include/ # 公共头文件(对外接口)
│ ├── engine.h # 执行引擎层接口
│ ├── parser.h # 解析器接口
│ └── storage.h # 存储引擎接口(KV存取)
├── src/
│ ├── main.c # 交互入口(REPL命令行)
│ ├── engine.c # 逻辑调度器,处理查询请求
│ ├── parser.c # 语句解析器,将文本解析为结构化请求
│ └── storage.c # 简单的内存KV存储
└── CMakeLists.txt # 构建配置文件2.10 流程梳理
main.c:命令行交互入口(REPL)
-
作用:读取用户输入字符串(例如
SET x 100),交给 parser 分析,最终通过 engine 执行。 -
模拟一个 SQL shell。
-
示例输入:
> SET name Alice > GET name
parser.[c/h]:命令解析器(Parser)
-
功能:将输入的命令行字符串转为结构化的
Statement结构体。 -
实现了对
SET,GET,CREATE的基本语法识别。 -
示例:
Statement stmt = parse("SET foo bar"); // stmt.type = STATEMENT_SET // stmt.key = "foo" // stmt.value = "bar"
engine.[c/h]:执行引擎(Engine)
-
功能:调度执行语义。
- 接收
Statement,根据类型(SET/GET/CREATE)转发给对应的存储模块。 - 保持各层解耦,方便替换底层(如未来支持持久化或SQL语义)。
- 接收
-
示例:
engine_execute(&stmt);
storage_memory.[c/h]:内存KV存储实现(Storage)
- 功能:实现一个极简的 Key-Value 哈希表,基于链表或数组。
- 操作支持:
create_table()set_key_value("foo", "bar")get_key_value("foo")→ 返回"bar"
2.11 源代码
storage.h和storage.c
include/storage.h
#ifndef STORAGE_H
#define STORAGE_H
typedef struct Storage Storage;
// 创建和释放存储实例
Storage* storage_create();
void storage_free(Storage* storage);
// 设置键值对
int storage_set(Storage* storage, const char* key, const char* value);
// 获取键对应的值(返回内部静态指针,不要 free)
const char* storage_get(Storage* storage, const char* key);
#endifsrc/storage.c
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include "../include/storage.h"
#define MAX_ITEMS 1024
#define KEY_SIZE 128
#define VALUE_SIZE 256
typedef struct {
char key[KEY_SIZE];
char value[VALUE_SIZE];
} KvPair;
struct Storage {
KvPair items[MAX_ITEMS];
int count;
};
Storage* storage_create() {
Storage* s = malloc(sizeof(Storage));
if (s) {
s->count = 0;
}
return s;
}
void storage_free(Storage* s) {
free(s);
}
int storage_set(Storage* s, const char* key, const char* value) {
for (int i = 0; i < s->count; ++i) {
if (strcmp(s->items[i].key, key) == 0) {
strncpy(s->items[i].value, value, VALUE_SIZE);
return 0;
}
}
if (s->count >= MAX_ITEMS) return -1;
strncpy(s->items[s->count].key, key, KEY_SIZE);
strncpy(s->items[s->count].value, value, VALUE_SIZE);
s->count++;
return 0;
}
const char* storage_get(Storage* s, const char* key) {
for (int i = 0; i < s->count; ++i) {
if (strcmp(s->items[i].key, key) == 0) {
return s->items[i].value;
}
}
return NULL;
}parser.h和parser.c
include/parser.h
#ifndef PARSER_H
#define PARSER_H
typedef enum {
CMD_SET,
CMD_GET,
CMD_UNKNOWN
} CommandType;
typedef struct {
CommandType type;
char key[128];
char value[256]; // 仅在 SET 使用
} KvCommand;
int parse_input(const char* input, KvCommand* cmd);
#endifsrc/parser.c
#include <string.h>
#include <stdio.h>
#include "../include/parser.h"
int parse_input(const char* input, KvCommand* cmd) {
char op[16] = {0};
int matched = sscanf(input, "%15s %127s %255[^\n]", op, cmd->key, cmd->value);
if (matched == 2 && strcmp(op, "GET") == 0) {
cmd->type = CMD_GET;
return 0;
} else if (matched == 3 && strcmp(op, "SET") == 0) {
cmd->type = CMD_SET;
return 0;
}
cmd->type = CMD_UNKNOWN;
return -1;
}engine.h和engine.c
include/engine.h
#ifndef ENGINE_H
#define ENGINE_H
#include "parser.h"
#include "storage.h"
int engine_execute(Storage* storage, const KvCommand* cmd);
#endifsrc/engine.c
#include <stdio.h>
#include "../include/engine.h"
int engine_execute(Storage* storage, const KvCommand* cmd) {
switch (cmd->type) {
case CMD_SET:
storage_set(storage, cmd->key, cmd->value);
printf("OK\n");
return 0;
case CMD_GET: {
const char* val = storage_get(storage, cmd->key);
if (val) printf("%s\n", val);
else printf("NULL\n");
return 0;
}
default:
printf("Error: unknown command.\n");
return 1;
}
}main.c(REPL 主程序)
#include <stdio.h>
#include <string.h>
#include "../include/parser.h"
#include "../include/engine.h"
#include "../include/storage.h"
int main() {
Storage* store = storage_create();
char input[512];
KvCommand cmd;
printf("MiniKV > ");
while (fgets(input, sizeof(input), stdin)) {
if (parse_input(input, &cmd) == 0) {
engine_execute(store, &cmd);
} else {
printf("Invalid command.\n");
}
printf("MiniKV > ");
}
storage_free(store);
return 0;
}CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(MiniKV C)
set(CMAKE_C_STANDARD 99)
include_directories(include)
add_executable(minikv
src/main.c
src/parser.c
src/engine.c
src/storage.c
)然后编译运行:
mkdir build && cd build
cmake ..
make
./minikv2.12 Git版本控制
Git 是一个分布式版本控制系统,用于跟踪文件的变化,特别是源代码文件的变化。它允许多个开发者协同工作,管理项目的源代码,并能够在团队合作中避免和解决冲突。
可以先直接跳转去附录学习一下,然后跟着视频做,这里我写一些简单的命令:
-
git init:初始化一个新的 Git 仓库,创建
.git目录,用于跟踪项目中的文件变化。git init -
git clone <repo_url>:从远程仓库克隆一个 Git 仓库到本地。
git clone https://github.com/user/repo.git -
git status:查看工作区文件的当前状态,查看哪些文件被修改、哪些文件处于暂存区等。
git status -
git add :将文件添加到暂存区,准备提交。
git add filename -
git commit -m “message”:将暂存区的修改提交到本地仓库,并附上提交信息。
git commit -m "Fixed a bug in the login module" -
git log:查看提交历史,按时间顺序列出所有提交记录。
git log -
git branch:查看当前的分支。
git branch -
git checkout :切换到另一个分支。
git checkout feature-branch -
git merge :将某个分支的修改合并到当前分支。
git merge feature-branch
我们这一次会在dev分支开发,然后main分支发布稳定的版本。
git add *
git commit
git co -b main
git merge dev
git tag -a v0.1.0 -m "release: 实现基础"第三章:实现内置 HTTP Server(http_server.c)
git checkout -b feature/http3.1 HTTP Server 原理
HTTP Server 是一个基于 TCP 的 请求-响应模型,服务端监听某端口,等待客户端(通常是浏览器)发送 HTTP 报文,并返回响应。
HTTP流程
浏览器 -> TCP连接 -> HTTP请求 -> 解析请求 -> 处理逻辑 -> 生成响应 -> 返回HTTP响应 -> 关闭或保持连接- socket监听(listen)
- 监听指定端口(如80/8080),等待客户端连接(accept)。
- TCP连接建立
- 客户端发起三次握手,服务器 accept 成功返回连接 fd。
- 接收请求报文
- 使用
read()或recv()读取数据(GET /index.html HTTP/1.1\r\n...)。
- 使用
- 解析 HTTP 请求
- 按协议分解:请求行、头部、空行、可选 body。
- 执行业务逻辑
- 查找资源或调用后端服务,生成响应内容。
- 构造 HTTP 响应报文
- 包括状态行、响应头、空行、body。
- 发送响应并关闭或保持连接
- 默认 HTTP/1.0 关闭,HTTP/1.1 若头部含
Connection: keep-alive,则保持。
- 默认 HTTP/1.0 关闭,HTTP/1.1 若头部含
HTTP的重要模块
| 模块 | 功能说明 |
|---|---|
| socket层 | 网络传输(TCP协议) |
| request解析 | 将原始报文解析为结构体 |
| router/dispatch | 路由请求到对应业务逻辑 |
| response生成 | 输出 HTTP 响应字符串 |
| 日志/Error | 打印访问日志和错误信息 |
HTTP 报文结构(简化)
请求(Request)示例:
GET /hello HTTP/1.1
Host: example.com
User-Agent: curl/7.68.0响应(Response)示例:
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Length: 5
Hello3.2 Http涉及的系统调用(C语言)
socket()→ 创建监听 socketbind()→ 绑定地址端口listen()→ 开始监听accept()→ 接受客户端连接read()/recv()→ 读取请求write()/send()→ 发送响应close()→ 关闭连接
理论铺垫完了,开始实现吧!
3.3 尝试实现http_server
include/http_server.h
#ifndef HTTP_SERVER_H
#define HTTP_SERVER_H
#include "storage.h"
void http_server_start(Storage* store, int port);
#endifsrc/http_server.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <netinet/in.h>
#include "../include/http_server.h"
#include "../include/parser.h"
#include "../include/engine.h"
#define PORT_DEFAULT 8080
#define BUFFER_SIZE 4096
void handle_client(int client_sock, Storage* store) {
char buffer[BUFFER_SIZE];
int bytes = recv(client_sock, buffer, sizeof(buffer) - 1, 0);
if (bytes <= 0) return;
buffer[bytes] = '\0';
// 简单提取 POST /api/query
if (strncmp(buffer, "POST /api/query", 15) != 0) {
const char* err = "HTTP/1.0 404 Not Found\r\nContent-Length: 0\r\n\r\n";
send(client_sock, err, strlen(err), 0);
return;
}
// 查找请求体(body)
char* body = strstr(buffer, "\r\n\r\n");
if (!body) return;
body += 4; // skip \r\n\r\n
// 解析 SQL 并执行
KvCommand cmd;
char response[512];
if (parse_input(body, &cmd) == 0) {
engine_execute(store, &cmd, response, sizeof(response));
} else {
snprintf(response, sizeof(response), "{\"error\": \"invalid command\"}");
}
char http_response[1024];
snprintf(http_response, sizeof(http_response),
"HTTP/1.0 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s",
strlen(response), response);
send(client_sock, http_response, strlen(http_response), 0);
}
void http_server_start(Storage* store, int port) {
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1) {
perror("socket");
exit(1);
}
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(port),
.sin_addr.s_addr = INADDR_ANY
};
if (bind(server_fd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
perror("bind");
close(server_fd);
exit(1);
}
if (listen(server_fd, 5) < 0) {
perror("listen");
close(server_fd);
exit(1);
}
printf("HTTP server running on port %d...\n", port);
while (1) {
int client_sock = accept(server_fd, NULL, NULL);
if (client_sock >= 0) {
handle_client(client_sock, store);
close(client_sock);
}
}
close(server_fd);
}3.5 重构engine_execute函数
注意一下,这是原来的engine_execute。
int engine_execute(Storage* storage, const KvCommand* cmd);而我们需求的新engine_execute是这样的
engine_execute(store, &cmd, response, sizeof(response)); // ❌ 错误
你会发现engine_execute 的用途变多了:
- 在 CLI 模式下,只需要执行命令,把结果打在控制台(
stdout) - 在 HTTP 模式下,需要执行命令,把结果写入字符串(JSON)缓冲区
所以我们要重构 engine_execute这个函数了,本次重构大概有三个原因:
函数的职责发生变化了:原来它只负责执行,输出直接用 printf。现在它还要把输出写进一个字符串(以供 HTTP 响应使用)。
当前设计不支持“多样性”:输出路径写死在 engine_execute 里,就只能支持 CLI。如果继续往里加 if (cli_mode)、if (http_mode),会使函数变得臃肿、难以维护。
违反单一职责原则(SRP):函数即负责逻辑执行,又负责输出呈现。更合理的设计应是:执行返回结构 → 呈现由调用者负责。
设计大于实现!这是我一直认为的,好的设计可以随时修改,坏的设计兼容不了。
那解决方案?
方案 A:改名 保留兼容性并迅速推进项目
int engine_execute(Storage*, const KvCommand*); // 只执行,输出 stdout
int engine_execute_with_result(Storage*, const KvCommand*, char* buf, size_t buf_size); // 执行+填充 JSON
方案B:返回结构体 计划持续扩展命令系统,统一返回结构体,增强可维护性。
typedef struct {
int code;
char message[256]; // 可填 JSON
} ExecutionResult;
ExecutionResult engine_execute(Storage*, const KvCommand*);重构后的engine文件
- 修改
engine.h文件,定义ExecutionResult结构体和新接口
#ifndef ENGINE_H
#define ENGINE_H
#include "parser.h"
#include "storage.h"
typedef struct {
int code; // 返回的状态码,0为成功,非0为失败
char message[256]; // 存储JSON响应
} ExecutionResult;
// 执行命令,返回执行结果
ExecutionResult engine_execute(Storage* storage, const KvCommand* cmd);
#endif- 修改
engine.c文件,更新engine_execute函数实现
#include "engine.h"
#include "storage.h"
#include <stdio.h>
#include <string.h>
ExecutionResult engine_execute(Storage* storage, const KvCommand* cmd) {
ExecutionResult result = {0}; // 默认返回成功
switch (cmd->type) {
case CMD_SET:
// 执行 SET 命令
if (storage_set(storage, cmd->key, cmd->value) == 0) {
snprintf(result.message, sizeof(result.message), "{\"status\": \"ok\"}");
result.code = 0; // 成功
} else {
snprintf(result.message, sizeof(result.message), "{\"error\": \"set failed\"}");
result.code = -1; // 失败
}
break;
case CMD_GET:
// 执行 GET 命令
const char* val = storage_get(storage, cmd->key);
if (val) {
snprintf(result.message, sizeof(result.message), "{\"value\": \"%s\"}", val);
result.code = 0; // 成功
} else {
snprintf(result.message, sizeof(result.message), "{\"error\": \"not found\"}");
result.code = -1; // 失败
}
break;
default:
snprintf(result.message, sizeof(result.message), "{\"error\": \"unknown command\"}");
result.code = -1; // 失败
break;
}
return result;
}- 使用新接口修改
main.c中的run_cli_mode函数
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "../include/parser.h"
#include "../include/engine.h"
#include "../include/storage.h"
#include "../include/http_server.h"
int run_cli_mode() {
Storage* store = storage_create();
if (!store) {
perror("Failed to create storage");
return -1;
}
char input[512];
KvCommand cmd;
printf("MiniKV > ");
while (fgets(input, sizeof(input), stdin)) {
if (parse_input(input, &cmd) == 0) {
ExecutionResult result = engine_execute(store, &cmd);
printf("%s\n", result.message);
} else {
printf("Invalid command.\n");
}
printf("MiniKV > ");
}
storage_free(store);
return 0;
}
int run_http_mode() {
Storage* store = storage_create();
if (!store) {
perror("Failed to create storage");
return -1;
}
// 启动 HTTP 服务器
http_server_start(store, 8080); // 启动 HTTP 服务,监听 8080 端口
storage_free(store);
return 0;
}
int main() {
int mode;
printf("Choose mode: 1 for CLI, 2 for HTTP: ");
scanf("%d", &mode);
getchar(); // 捕获换行符
if (mode == 1) {
// CLI 模式
return run_cli_mode();
} else if (mode == 2) {
// HTTP 模式
return run_http_mode();
} else {
printf("Invalid mode selected.\n");
return -1;
}
}重构的Git提交
3.6 新的http_server
src/http_server.c
#include "http_server.h"
#include "engine.h"
#include "parser.h"
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 1024
// 处理客户端请求
void handle_client(int client_sock, Storage* store) {
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
// 读取客户端请求
bytes_read = read(client_sock, buffer, sizeof(buffer) - 1);
if (bytes_read <= 0) {
perror("read");
close(client_sock);
return;
}
buffer[bytes_read] = '\0'; // 确保字符串结尾
// 找到请求体(跳过请求头)
char* body = strstr(buffer, "\r\n\r\n");
if (!body || strlen(body) < 4) {
const char* msg = "{\"error\": \"Malformed request\"}";
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 400 Bad Request\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
return;
}
body += 4; // 跳过 "\r\n\r\n",body 现在指向请求体部分
// 解析 SQL 命令
KvCommand cmd;
if (parse_input(body, &cmd) != 0) {
const char* msg = "{\"error\": \"Invalid command\"}";
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 400 Bad Request\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
return;
}
// 执行命令
ExecutionResult result = engine_execute(store, &cmd);
// 构建 JSON 响应
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(result.message), result.message);
write(client_sock, response, strlen(response));
// 关闭连接
close(client_sock);
}
// 启动 HTTP 服务
void http_server_start(Storage* store, int port) {
int server_sock, client_sock;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
server_sock = socket(AF_INET, SOCK_STREAM, 0);
if (server_sock < 0) {
perror("socket");
exit(1);
}
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(port);
if (bind(server_sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
close(server_sock);
exit(1);
}
if (listen(server_sock, 5) < 0) {
perror("listen");
close(server_sock);
exit(1);
}
printf("HTTP server started on port %d...\n", port);
while (1) {
client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &client_len);
if (client_sock < 0) {
perror("accept");
continue;
}
handle_client(client_sock, store);
}
close(server_sock);
}然后要进行一次git提交与分支合并,在main分支完成一次tag。
git tag -a v0.2.0 -m "release: v0.2.0:完成http服务的搭建"第四章:API处理层
4.1 API是什么
API(Application Programming Interface,应用程序编程接口) 是软件系统中用于不同模块、组件之间 通信与协作的接口规范。它定义了一组函数、数据结构、通信协议,使得不同程序(或系统)之间可以相互调用而无需了解彼此内部的实现细节。
回忆一下:API 就是模块之间“约定好的沟通语言”,你只需知道怎么用,不需要知道里面是怎么实现的。
假设我写了一个键值存储系统,暴露了这个 API:
int kv_put(const char* key, const char* value);
char* kv_get(const char* key);你调用这两个函数即可读写数据,但无需知道我底层用了哈希表、B+树,还是黑魔法。
4.2 HTTP API (Web服务):
如果你用浏览器或 curl 发:
curl -X POST http://localhost:8080/api/query -d '{"sql": "GET name"}'这是调用 HTTP 服务的 RESTful API,服务器接收到这个请求后,解析 SQL 执行,然后返回 JSON 响应。
可以说:HTTP 是传输方式,REST 是风格,而 API 是协议本身的抽象
4.3 实现api_handler
现在我们将引入一个专门的组件,来处理 HTTP 请求中的 URI 路径、POST 参数(例如 /api/query 中包含的 SQL),并调用已有的解析器、执行引擎、KV 存储,最终生成 JSON 格式的响应。
新增文件:
├── include/
│ └── api_handler.h // 声明 API 处理接口
├── src/
│ └── api_handler.c // 实现 API 路由处理逻辑1:定义接口(include/api_handler.h)
#ifndef API_HANDLER_H
#define API_HANDLER_H
#include "storage.h"
// 处理 API 请求(传入路径、正文内容,输出 JSON 响应)
void handle_api_request(Storage* store, const char* path, const char* body, char* response, int max_len);
#endifStep 2:实现逻辑(src/api_handler.c)
#include "api_handler.h"
#include "parser.h"
#include "engine.h"
#include <stdio.h>
#include <string.h>
// 支持 POST /api/query
void handle_api_request(Storage* store, const char* path, const char* body, char* response, int max_len) {
if (strcmp(path, "/api/query") != 0) {
snprintf(response, max_len, "{\"error\": \"Unknown API endpoint\"}");
return;
}
// 解析 body 为 KvCommand
KvCommand cmd;
if (parse_input(body, &cmd) != 0) {
snprintf(response, max_len, "{\"error\": \"Invalid query syntax\"}");
return;
}
// 执行命令
ExecutionResult result = engine_execute(store, &cmd);
// 构造 JSON 响应(假设 message 为 JSON 片段)
snprintf(response, max_len, "%s\n", result.message);
}Step 3:在 http_server.c 中调用 handler
在 handle_client() 函数中提取 URI 和请求体后调用:
#include "api_handler.h" // 加在开头
// 在解析请求后加入
if (strncmp(request_line, "POST /api/query", 15) == 0) {
// ... 读取 body ...
char api_response[BUFFER_SIZE];
handle_api_request(store, "/api/query", body, api_response, sizeof(api_response));
// 构造 HTTP 响应
}Step 4:修改 CMakeLists.txt 加入 api_handler
add_executable(minikv
src/main.c
src/parser.c
src/engine.c
src/storage.c
src/http_server.c
src/api_handler.c # 添加此行
)新的server_http.c
#include "http_server.h"
#include "api_handler.h"
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 1024
// 处理客户端请求
void handle_client(int client_sock, Storage* store) {
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
// 读取客户端请求
bytes_read = read(client_sock, buffer, sizeof(buffer) - 1);
if (bytes_read <= 0) {
perror("read");
close(client_sock);
return;
}
buffer[bytes_read] = '\0'; // 确保字符串结尾
// 提取 HTTP 方法和路径
char method[8], path[64];
if (sscanf(buffer, "%7s %63s", method, path) != 2) {
const char* msg = "{\"error\": \"Malformed request line\"}";
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 400 Bad Request\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
return;
}
// 找到请求体
char* body = strstr(buffer, "\r\n\r\n");
if (!body || strlen(body) < 4) {
const char* msg = "{\"error\": \"Missing request body\"}";
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 400 Bad Request\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
return;
}
body += 4; // 跳过 "\r\n\r\n"
// 使用 API 处理模块生成响应体
char msg[BUFFER_SIZE];
handle_api_request(store, path, body, msg, sizeof(msg));
// 构建完整 HTTP 响应
char response[BUFFER_SIZE * 2]; // 预留更大空间
snprintf(response, sizeof(response),
"HTTP/1.0 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
}
// 启动 HTTP 服务
void http_server_start(Storage* store, int port) {
int server_sock, client_sock;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
server_sock = socket(AF_INET, SOCK_STREAM, 0);
if (server_sock < 0) {
perror("socket");
exit(1);
}
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(port);
if (bind(server_sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
close(server_sock);
exit(1);
}
if (listen(server_sock, 5) < 0) {
perror("listen");
close(server_sock);
exit(1);
}
printf("HTTP server started on port %d...\n", port);
while (1) {
client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &client_len);
if (client_sock < 0) {
perror("accept");
continue;
}
handle_client(client_sock, store);
}
close(server_sock);
}4.4 curl 测试一下
curl -X POST http://localhost:8080/api/query -d "SET name Tom"
curl -X POST http://localhost:8080/api/query -d "GET name"记得Git提交一下。
第五章:构建前端页面
5.1 用户看到的一切都是前端
前端(Frontend) 是指用户可以直接看到并与之交互的 客户端界面部分,通常运行在浏览器中。它负责展示内容、处理用户操作、与后端服务器通信并渲染动态数据。
前端就是“用户看到的一切”,包括网页界面、按钮、动画、表单、图表等,它是用户与系统交互的入口。
你打开某个电商网站:
- 页面结构(HTML):有产品名、价格、按钮。
- 样式(CSS):产品图居中、价格是红色的、响应式适配手机。
- 行为(JS):点击“加入购物车”按钮时执行动画并发送请求。
这些都是前端做的事。
5.2 重构handler
在构建 index.html + style.css + app.js之前我想先重构一下handler.c,在了解了API的重要性后,我打算定义一个面向“请求分发”的 API 路由处理中心,核心目的是为 HTTP 服务增加一个统一的“请求分发中心”,将不同 URI 路径映射到不同的处理逻辑,从而做到结构清晰、职责分离。
不同的路径返回不同的东西
/ -> index.html
/app.js -> app.js
/style.css -> style.css
/api/query -> parser.h -> engine -> storage
我选用策略模式(Strategy Pattern)来解决问题,这是一种行为型设计模式,它的核心思想是:将一组可变的行为(算法/处理逻辑)封装成独立的“策略类”,在运行时根据上下文选择合适的策略执行,从而实现行为的解耦与可扩展。
搞个表出来,然后对照着表,不同的api用不同对的函数处理。
api_handle.h
#ifndef API_HANDLER_H
#define API_HANDLER_H
#include "storage.h"
// 所有 API 处理函数的签名
typedef void (*ApiHandlerFn)(Storage* store, const char* body, char* response, int max_len);
// 路由器主入口
void handle_api_request(Storage* store, const char* path, const char* body, char* response, int max_len);
#endifapi_handle.c
#include "api_handler.h"
#include "parser.h"
#include "engine.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// 每个路径对应一个处理函数
static void handle_query(Storage* store, const char* body, char* response, int max_len) {
KvCommand cmd;
if (parse_input(body, &cmd) != 0) {
snprintf(response, max_len, "{\"error\": \"Invalid query syntax\"}\n");
return;
}
ExecutionResult result = engine_execute(store, &cmd);
snprintf(response, max_len, "%s\n", result.message);
}
static void handle_health(Storage* store, const char* body, char* response, int max_len) {
(void)store; // unused
(void)body;
snprintf(response, max_len, "{\"status\": \"ok\"}\n");
}
// 处理 / 请求,返回 index.html 文件内容
static void handle_index(Storage* store, const char* body, char* response, int max_len) {
(void)store; // unused
(void)body;
// 读取 index.html 文件内容
FILE* file = fopen("web/index.html", "r");
if (!file) {
snprintf(response, max_len, "{\"error\": \"index.html not found\"}\n");
return;
}
// 读取文件内容并构建响应
char file_content[1024];
size_t bytes_read = fread(file_content, 1, sizeof(file_content) - 1, file);
if (bytes_read < 0) {
snprintf(response, max_len, "{\"error\": \"Failed to read index.html\"}\n");
fclose(file);
return;
}
file_content[bytes_read] = '\0'; // 确保字符串结束
// 构造响应头
snprintf(response, max_len,
"HTTP/1.0 200 OK\r\n"
"Content-Type: text/html\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", bytes_read, file_content);
fclose(file);
}
// 定义路由表
typedef struct {
const char* path;
ApiHandlerFn handler;
} ApiRoute;
static ApiRoute routes[] = {
{ "/api/query", handle_query },
{ "/api/health", handle_health },
{ "/", handle_index }, // 新增:返回 index.html
};
#define NUM_ROUTES (sizeof(routes) / sizeof(routes[0]))
// 调度器
void handle_api_request(Storage* store, const char* path, const char* body, char* response, int max_len) {
for (size_t i = 0; i < NUM_ROUTES; ++i) {
if (strcmp(path, routes[i].path) == 0) {
routes[i].handler(store, body, response, max_len);
return;
}
}
snprintf(response, max_len, "{\"error\": \"Unknown API endpoint\"}\n");
}修改http_server.c
#include "http_server.h"
#include "api_handler.h"
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 2048
/
* @brief 处理客户端请求,包括解析请求、路由匹配并构造响应。
*
* @param client_sock 客户端 socket 文件描述符
* @param store 指向 Storage 对象的指针
*/
void handle_client(int client_sock, Storage* store) {
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
bytes_read = read(client_sock, buffer, sizeof(buffer) - 1);
if (bytes_read <= 0) {
perror("read");
close(client_sock);
return;
}
buffer[bytes_read] = '\0';
// 解析请求行
char method[8], path[128];
if (sscanf(buffer, "%7s %127s", method, path) != 2) {
const char* msg = "{\"error\": \"Malformed request line\"}";
char response[BUFFER_SIZE];
snprintf(response, sizeof(response),
"HTTP/1.0 400 Bad Request\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
close(client_sock);
return;
}
// 查找请求体
char* body = strstr(buffer, "\r\n\r\n");
if (body) {
body += 4;
} else {
body = "";
}
// 响应缓存
char msg[BUFFER_SIZE * 2];
memset(msg, 0, sizeof(msg));
// 是否为完整响应(含 HTTP 头),用于区分 HTML vs JSON
int is_full_http_response = 0;
// 分发请求
handle_api_request(store, path, body, msg, sizeof(msg));
// 如果返回内容以 "HTTP/" 开头,视为完整响应(如 handle_index 返回)
if (strncmp(msg, "HTTP/", 5) == 0) {
is_full_http_response = 1;
}
if (is_full_http_response) {
// 已包含完整 HTTP 头
write(client_sock, msg, strlen(msg));
} else {
// 标准 JSON 响应包裹 HTTP 头
char response[BUFFER_SIZE * 2];
snprintf(response, sizeof(response),
"HTTP/1.0 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", strlen(msg), msg);
write(client_sock, response, strlen(response));
}
close(client_sock);
}
/
* @brief 启动 HTTP 服务,监听指定端口并处理每个客户端连接。
*
* @param store 指向 Storage 对象的指针
* @param port 要监听的端口号
*/
void http_server_start(Storage* store, int port) {
int server_sock, client_sock;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
server_sock = socket(AF_INET, SOCK_STREAM, 0);
if (server_sock < 0) {
perror("socket");
exit(EXIT_FAILURE);
}
int reuse = 1;
setsockopt(server_sock, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(port);
if (bind(server_sock, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
close(server_sock);
exit(EXIT_FAILURE);
}
if (listen(server_sock, 5) < 0) {
perror("listen");
close(server_sock);
exit(EXIT_FAILURE);
}
printf("HTTP server started on port %d...\n", port);
while (1) {
client_sock = accept(server_sock, (struct sockaddr*)&client_addr, &client_len);
if (client_sock < 0) {
perror("accept");
continue;
}
handle_client(client_sock, store);
}
close(server_sock);
}5.3 HTML+CSS+JS讲解
HTML 是超文本标记语言,用来定义网页内容的结构和元素。
CSS 是层叠样式表,用来定义 HTML 元素的样式,如颜色、大小、布局等。
JavaScript 是脚本语言,用来让网页动起来,实现交互和逻辑。
1. HTML:页面的结构
HTML (Hypertext Markup Language) 是用于创建网页的标准标记语言。它定义了网页的内容和结构,包括文本、图像、视频等元素。
示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>HTML, CSS, JS Example</title>
</head>
<body>
<h1>Hello, World!</h1>
<p id="message">This is a paragraph.</p>
<button id="changeText">Change Text</button>
</body>
</html>在这个示例中,<h1> 定义了一个标题,<p> 定义了一个段落,<button> 定义了一个按钮。
2. CSS:页面的样式
CSS (Cascading Style Sheets) 是用来定义网页元素的样式的,它控制布局、颜色、字体、间距等视觉效果。CSS 能够让网页看起来更加美观和有吸引力。
示例:
/* style.css */
body {
font-family: Arial, sans-serif;
background-color: #f4f4f4;
}
h1 {
color: #333;
}
button {
background-color: #4CAF50;
color: white;
padding: 10px 20px;
border: none;
cursor: pointer;
}
button:hover {
background-color: #45a049;
}在这个例子中,CSS 定义了 body 背景色、h1 的文字颜色、以及 button 的样式和 hover 效果。
3. JavaScript:页面的行为
JavaScript 是一种编程语言,用于为网页添加交互性。它可以响应用户的操作,比如点击按钮、提交表单、发送请求等。JavaScript 可以通过操作 DOM(文档对象模型)来修改 HTML 和 CSS。
示例:
// script.js
document.getElementById('changeText').addEventListener('click', function() {
document.getElementById('message').textContent = 'The text has been changed!';
});在这个例子中,JavaScript 代码监听了按钮的点击事件,并在按钮被点击时更改 <p> 标签的文本内容。
4. 它们是如何一起工作的?
HTML 负责结构:HTML 定义了网页的框架和内容。
CSS 负责样式:CSS 控制网页元素的视觉表现,使其美观且易于使用。
JavaScript 负责行为:JavaScript 赋予网页交互性和动态变化,比如响应用户点击、提交表单、与服务器通信等。
5. 与后端通信:发送一个请求
当需要与后端(服务器)通信时,JavaScript 使用 AJAX (Asynchronous JavaScript and XML) 或 Fetch API 来向服务器发送请求并处理响应。
示例:使用 fetch 发送一个 POST 请求到后端
假设我们有一个表单,用户输入一些信息后,点击按钮将数据发送到服务器。
HTML:
<form id="userForm">
<label for="username">Username:</label>
<input type="text" id="username" name="username">
<button type="submit">Submit</button>
</form>
<p id="responseMessage"></p>JavaScript(使用 fetch 向后端发送数据):
document.getElementById('userForm').addEventListener('submit', function(event) {
event.preventDefault(); // 防止表单默认提交
// 获取用户输入的数据
const username = document.getElementById('username').value;
// 发送 POST 请求到后端
fetch('https://example.com/api/submit', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ username: username })
})
.then(response => response.json()) // 处理响应的 JSON 数据
.then(data => {
document.getElementById('responseMessage').textContent = data.message;
})
.catch(error => {
console.error('Error:', error);
});
});6. 如何这个过程工作:
- 用户填写表单并点击提交按钮。
- JavaScript 捕获提交事件,阻止默认的表单提交。
fetchAPI 向后端发送一个 POST 请求,携带用户输入的数据(如username)。- 后端接收到请求后,处理数据并返回响应(通常是一个 JSON 格式的数据)。
- JavaScript 处理响应,并在页面上更新内容(例如显示服务器返回的消息)。
5.4 实现前端
web/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>MiniKV 控制台</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="console">
<h1>MiniKV Console</h1>
<textarea id="sqlInput" placeholder="请输入命令,如 SET a 123 或 GET a"></textarea>
<button onclick="sendQuery()">执行</button>
<pre id="resultArea">等待响应...</pre>
</div>
<script src="app.js"></script>
</body>
</html>web/style.css
body {
margin: 0;
background-color: #fff;
font-family: 'Courier New', Courier, monospace;
color: #000;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
}
.console {
border: 5px solid #000;
padding: 2rem;
width: 500px;
box-shadow: 10px 10px 0 #000;
background-color: #fdfdfd;
}
h1 {
font-size: 1.8rem;
margin-bottom: 1rem;
text-align: center;
border-bottom: 2px solid #000;
padding-bottom: 0.5rem;
}
button {
width: 100%;
padding: 0.7rem;
font-size: 1rem;
background-color: #000;
color: #fff;
border: none;
cursor: pointer;
transition: all 0.2s ease;
}
button:hover {
background-color: #444;
}
textarea,
pre {
width: 100%;
box-sizing: border-box;
font-size: 1rem;
border: 2px solid #000;
font-family: 'Courier New', Courier, monospace;
}
textarea {
height: 80px;
padding: 0.5rem;
resize: none;
margin-bottom: 1rem;
}
pre {
background: #eee;
padding: 1rem;
min-height: 100px;
overflow: auto;
white-space: pre-wrap;
}web/app.js
function sendQuery() {
const sql = document.getElementById("sqlInput").value;
fetch('/api/query', {
method: 'POST',
headers: {
'Content-Type': 'text/plain'
},
body: sql
})
.then(response => response.text())
.then(data => {
document.getElementById("resultArea").textContent = data;
})
.catch(error => {
document.getElementById("resultArea").textContent = `错误: ${error}`;
});
}然后我们运行build/minikv发现,访问localhost:8080发现html是有了,但是js和css都没。
这是因为没有添加静态文件支持
修改一下api_handler.c
#include "api_handler.h"
#include "parser.h"
#include "engine.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
/// 查询命令处理函数:解析 body 并执行
static void handle_query(Storage* store, const char* body, char* response, int max_len) {
KvCommand cmd;
if (parse_input(body, &cmd) != 0) {
snprintf(response, max_len, "{\"error\": \"Invalid query syntax\"}\n");
return;
}
ExecutionResult result = engine_execute(store, &cmd);
snprintf(response, max_len, "%s\n", result.message);
}
/// 健康检查处理函数
static void handle_health(Storage* store, const char* body, char* response, int max_len) {
(void)store;
(void)body;
snprintf(response, max_len, "{\"status\": \"ok\"}\n");
}
/// 返回 index.html 主页内容
static void handle_index(Storage* store, const char* body, char* response, int max_len) {
(void)store;
(void)body;
FILE* file = fopen("../web/index.html", "r");
if (!file) {
snprintf(response, max_len, "{\"error\": \"index.html not found\"}\n");
return;
}
char file_content[8192];
size_t bytes_read = fread(file_content, 1, sizeof(file_content) - 1, file);
file_content[bytes_read] = '\0';
fclose(file);
snprintf(response, max_len,
"HTTP/1.0 200 OK\r\n"
"Content-Type: text/html\r\n"
"Content-Length: %zu\r\n"
"\r\n"
"%s", bytes_read, file_content);
}
/// 静态资源通用处理器:支持 .css/.js/.html 等文件
static void handle_static(Storage* store, const char* body, char* response, int max_len, const char* path) {
(void)store;
(void)body;
// 构造完整文件路径
char filepath[256];
snprintf(filepath, sizeof(filepath), "../web%s", path);
FILE* file = fopen(filepath, "rb");
if (!file) {
snprintf(response, max_len, "HTTP/1.0 404 Not Found\r\nContent-Type: text/plain\r\n\r\nFile not found");
return;
}
struct stat st;
stat(filepath, &st);
size_t file_size = st.st_size;
// 判断 MIME 类型
const char* content_type = "application/octet-stream";
if (strstr(path, ".css")) {
content_type = "text/css";
} else if (strstr(path, ".js")) {
content_type = "application/javascript";
} else if (strstr(path, ".html")) {
content_type = "text/html";
} else if (strstr(path, ".png")) {
content_type = "image/png";
} else if (strstr(path, ".jpg") || strstr(path, ".jpeg")) {
content_type = "image/jpeg";
} else if (strstr(path, ".svg")) {
content_type = "image/svg+xml";
}
// 读取内容
char* file_content = malloc(file_size + 1);
fread(file_content, 1, file_size, file);
file_content[file_size] = '\0';
fclose(file);
snprintf(response, max_len,
"HTTP/1.0 200 OK\r\n"
"Content-Type: %s\r\n"
"Content-Length: %zu\r\n"
"\r\n", content_type, file_size);
memcpy(response + strlen(response), file_content, file_size);
response[strlen(response) + file_size] = '\0';
free(file_content);
}
/// 路由定义
typedef struct {
const char* path;
ApiHandlerFn handler;
} ApiRoute;
static ApiRoute routes[] = {
{ "/api/query", handle_query },
{ "/api/health", handle_health },
{ "/", handle_index }
};
#define NUM_ROUTES (sizeof(routes) / sizeof(routes[0]))
/// 请求调度器,根据 path 调用对应处理函数
void handle_api_request(Storage* store, const char* path, const char* body, char* response, int max_len) {
for (size_t i = 0; i < NUM_ROUTES; ++i) {
if (strcmp(path, routes[i].path) == 0) {
routes[i].handler(store, body, response, max_len);
return;
}
}
// fallback: 尝试作为静态文件处理
handle_static(store, body, response, max_len, path);
}5.5 查看效果
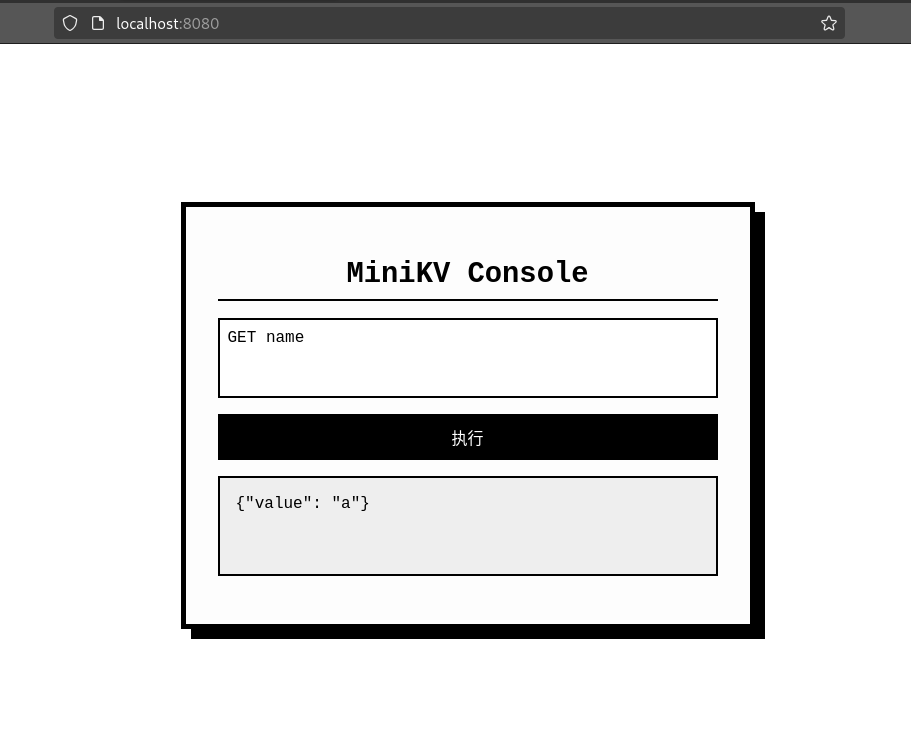
记得git一下。
git tag -a v0.3.0 -m "release: v0.3.0:完成web的搭建"第六章:测试与调试
测试很重要,因为有一个常用的方法就是测试驱动开发(Test-Driven Development, TDD)这是一种软件开发方法论,其核心理念是:先写测试,再写实现代码,整个过程围绕“让测试通过”这一目标进行迭代。
6.1 使用 Check 编写单元测试(测试 KV 引擎与 API 层)
使用 C 语言的 Check 框架编写测试用例,验证核心引擎逻辑和 API 层的正确性。
安装 Check:
sudo apt install check6.2 增加Check单元测试
test/test_storage.c
#include <check.h>
#include "../include/storage.h"
START_TEST(test_set_and_get) {
Storage* s = storage_create();
ck_assert_int_eq(storage_set(s, "hello", "world"), 0);
ck_assert_str_eq(storage_get(s, "hello"), "world");
storage_free(s);
}
END_TEST
Suite* storage_suite(void) {
Suite* s;
TCase* tc_core;
s = suite_create("Storage");
tc_core = tcase_create("Core");
tcase_add_test(tc_core, test_set_and_get);
suite_add_tcase(s, tc_core);
return s;
}
int main(void) {
int failed = 0;
Suite* s = storage_suite();
SRunner* runner = srunner_create(s);
srunner_run_all(runner, CK_NORMAL);
failed = srunner_ntests_failed(runner);
srunner_free(runner);
return (failed == 0) ? 0 : 1;
}CmakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(MiniKV C)
set(CMAKE_C_STANDARD 99)
# 包含头文件目录
include_directories(include)
# 主程序构建
add_executable(minikv
src/main.c
src/parser.c
src/engine.c
src/storage.c
)
# 构建测试程序
add_executable(test_storage
test/test_storage.c
src/storage.c
)
# 链接 Check 测试库(不依赖 find_package)
target_link_libraries(test_storage check subunit m pthread)
# 可选:启用测试集成(ctest)
enable_testing()
add_test(NAME StorageTest COMMAND test_storage)运行
cd build
cmake ..
make
ctest6.3 使用 curl 模拟 REST API 请求
使用 curl 工具对 HTTP 接口进行功能性测试。
-
查询接口测试:
curl -X POST http://localhost:8080/api/query -d '{"op":"set", "key":"a", "value":"1"}' curl -X POST http://localhost:8080/api/query -d '{"op":"get", "key":"a"}' -
健康检查接口:
curl http://localhost:8080/api/health -
首页与静态资源测试:
curl http://localhost:8080/ curl http://localhost:8080/style.css
6.4 使用 gdb 进行调试
推荐使用 gdb 对请求路径和数据处理流程进行调试。
启动调试:
gcc -g -o server main.c api_handler.c engine.c parser.c storage.c -o kvserver
gdb ./kvserver设置断点并运行:
break handle_api_request
run示例调试路径:
- 输入
/api/query请求 - 跟踪
handle_api_request -> engine_execute -> storage_set - 检查内存状态与结果
gdb如果不搭配IDE是不太好用的
可以有一个git co -b feature/test
第七章:部署与发布
我们之前做的所有事情都在虚拟机里面,虚拟机完全虚拟化了一个操作系统,所以一定会损失性能,所以我们需要一个新的容器来封装我们的项目,让他启动然后监听8080端口,以允许用户访问的时候获取index.html。同时每次的更新和重启也要快速,那么Docker应运而生。
Docker 是一种轻量级的容器化技术,它允许开发者将应用程序及其所有依赖封装为一个标准化的单元,在任何支持 Docker 的平台上以一致的方式运行。相比传统的虚拟机,Docker 容器更加高效、启动更快、资源开销更小。在当代软件部署实践中,Docker 提供了一种简洁而可控的环境隔离机制,使软件从开发到生产的迁移过程变得更加平滑。正因为如此,Docker 成为 DevOps 流程中不可或缺的基础设施工具之一,被广泛用于微服务架构、自动化测试、持续集成与部署等场景
Docker 的出现,不只是一个技术优化的成果,更是一种软件工程哲学。它代表着“不可变基础设施”(Immutable Infrastructure)的理念:将一切可变性尽量前置到构建阶段,从而保证部署的确定性与一致性,这就是软件工业化。
那我们现在来安装Docker!
我还记得我第一次安装Docker的时候直接运行了sudo apt install docker。然后发现有一点不对劲,因为Debian自带一个老旧的软件包也叫 docker,它不是我想要的 Docker Engine,而是一个和打印服务相关的过时玩意。
运行一下sudo apt show docker你会看到这玩意的介绍信息。
Description: System tray for KDE3/GNOME2 docklet applications7.1 安装Docker Engine
Docker 官方维护的是如下几个组件:
docker-ce(社区版)docker-ce-cli(命令行工具)containerd.io(容器运行时)docker-buildx-plugin(跨平台构建)docker-compose-plugin(新版 Compose)
所以我们要依次:
- 安装依赖组件
- 添加官方 GPG 密钥
- 添加 Docker 官方源
- 安装真正的 Docker
1、安装Docker的依赖组件:
sudo apt update
sudo apt install -y \
ca-certificates \
curl \
gnupg \
lsb-release2、添加 Docker 官方 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | \
sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg3、添加稳定版 Docker 仓库
echo \
"deb [arch=$(dpkg --print-architecture) \
signed-by=/etc/apt/keyrings/docker.gpg] \
https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null4、安装 Docker Engine 本体
sudo apt update
sudo apt install -y \
docker-ce \
docker-ce-cli \
containerd.io \
docker-buildx-plugin \
docker-compose-pluginDocker 官方服务器有时因 CDN/区域问题在中国访问较慢或被干扰。
可以切换为国内镜像源:
sudo sed -i 's|download.docker.com|mirrors.ustc.edu.cn/docker-ce|g' /etc/apt/sources.list.d/docker.list
sudo apt-get update5、(建议)配置非 root 用户使用 Docker
sudo usermod -aG docker $USER
newgrp docker测试 Docker 是否可用
docker run hello-world应输出:
Hello from Docker!
This message shows that your installation appears to be working correctly.6、附:验证环境与版本
docker --version
# 示例:Docker version 24.x.x, build xxxxxxx
docker info
# 查看守护进程、存储驱动、是否 rootless 等信息7.2 Docker基础教学
接下来我们简单学习一下Docker的使用,Docker 的基本使用可以概括为三个关键步骤:构建镜像、运行容器、管理资源。首先,通过一个称为 Dockerfile 的描述文件,开发者可以定义一个应用所需的环境与命令,并用 docker build 构建出镜像(image)。其次,使用 docker run 命令可以基于镜像创建并启动一个容器(container),该容器即为应用的运行实例。最后,通过 docker ps 查看容器状态,docker stop、rm 管理生命周期,从而实现对容器的全流程控制。
看一个例子,假设我们有这样一个项目,项目名为 myapp,
主文件main.go路由localhost:8080/
返回
<h1>Hello,Docker.</h1>项目目录结构如下:
myapp/
├── Dockerfile
├── go.mod # go的依赖
└── main.go # 启动一个http_server监听8080端口,返回Hello,Docker.-
写一下
Dockerfile:定义环境、复制文件、声明启动命令,例如:# 使用官方 Go 语言镜像作为构建基础 FROM golang:1.21 # 设置工作目录 WORKDIR /app # 复制所有本地文件到容器中 COPY . . # 构建 Go 应用 RUN go build -o main . # 设置默认启动命令 CMD ["./main"] -
构建镜像:
# 构建镜像 docker build -t myapp . -
运行容器:
# 启动容器并映射端口 docker run -p 8080:8080 myapp到这里,我们就可以访问浏览器访问 http://localhost:8080 看到显示:
Hello, Docker! -
查看与管理容器:
docker ps # 查看运行中容器 docker stop ID # 停止容器 docker rm ID # 删除容器
专业一点说这就是“环境即代码”。在传统部署中,环境配置依赖手工操作,难以复现,极易出错。而 Dockerfile 提供了一种结构化的方式,可以记录下构建环境的全过程。
我从基础的FROM golang:1.21启动,然后依次执行Dockerfile里的命令,无论是谁在什么时候我们构建出来的软件都是一模一样的。
基础设施也是代码:开发者能够像管理源代码一样管理运行环境。它不仅有助于提升协作效率,毕竟你也不想遇到“哥,为什么我运行不了你的代码啊?”这种情况吧。统一了环境之后的自动化测试、灰度发布、多环境部署也顺理成章了。
把复杂的软件与其依赖封装成黑盒,接口明确,行为确定。函数->容器化->微服务
7.3 为我们的项目编写一下Dockerfile
准备文件
mkdir docker
touch docker/Dockerfile
nvim docker/Dockerdile编写Dockerfile
FROM debian:bookworm
# 设置时区与非交互模式以防卡死
ENV DEBIAN_FRONTEND=noninteractive
# 安装构建和调试所需工具
RUN apt update && apt install -y \
git \
cmake \
clang \
check \
gdb \
curl \
tree \
build-essential \
pkg-config \
ca-certificates \
&& rm -rf /var/lib/apt/lists/*
# 创建工作目录并进入
WORKDIR /app
# 默认进入 shell,支持挂载 + 编译 + 调试
CMD ["/bin/bash"]构建出开发镜像,原理就是docker按照dockerfile的命令,自己运行一遍生成一个Debian容器:
docker build -t minikv-dev ./docker7.4 Docker构建与代理设置
欸,为什么运行不了,因为网络问题。Docker的服务器被禁止访问力,所以我们有两个方案。
A、使用Docker镜像
编辑 /etc/docker/daemon.json(如果没有就新建):
填入类似以下的内容,你需要自己网上找可以用的镜像源,失效的很快,我建议方案B。
{
"registry-mirrors": [
"https://mirror.baidubce.com",
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}然后重启 Docker:
sudo systemctl daemon-reexec
sudo systemctl restart dockerB、(推荐)设置网络代理
做两件事,
1、为 Docker 守护进程设置 HTTP/HTTPS 代理
2、为Docker本身设置代理,就是运行docker build -t minikv-dev ./docker 时传入代理
为 Docker 守护进程设置 HTTP/HTTPS 代理可以让 Docker 拉取镜像时走代理。
- 创建代理配置目录
sudo mkdir -p /etc/systemd/system/docker.service.d- 创建代理配置文件
sudo nano /etc/systemd/system/docker.service.d/http-proxy.conf3、写入以下内容(按需更换 http_proxy 和 https_proxy):
我的虚拟机是桥接网卡,主机ip是192.168.31.35,clash允许局域网连接开放的7890端口。
[Service]
Environment="HTTP_PROXY=http://192.168.31.35:7890"
Environment="HTTPS_PROXY=http://192.168.31.35:7890"
Environment="NO_PROXY=localhost,127.0.0.1"注意:如果代理是 SOCKS5(如 Clash 或 V2Ray 默认端口),可以使用
socks5h://192.168.31.35:7890,但 Docker 不原生支持 SOCKS5,建议搭配 Privoxy 转换为 HTTP 代理,提一下,一般用不上。
4、重新加载并重启 Docker
sudo systemctl daemon-reexec
sudo systemctl daemon-reload
sudo systemctl restart docker5、验证设置是否生效
docker info | grep -i proxy应该输出设置的 HTTP_PROXY 和 HTTPS_PROXY。
6、然后我们为 docer build 指定代理,这里我建议直接用命令行参数传入就可以了。
在命令中指定 --build-arg
docker build \
--build-arg HTTP_PROXY=http://192.168.31.35:7890 \
--build-arg HTTPS_PROXY=http://192.168.31.35:7890 \
-t minikv-dev ./docker如果你使用 SOCKS5,Docker build 不原生支持,建议通过 Privoxy 转换为 HTTP 代理。
原理就是我们用–build-arg HTTP_PROXY 定义了一个ARG变量(在构建时定义的变量,构建过程结束后,这些变量不会保留在最终镜像中。)构建过程结束,也就是容器开始运行的时候代理就会失效,那怎么在容器运行时使用这些代理环境变量呢?
首先我们需要在 Dockerfile 中使用 ARG 显式声明来接受外部传入的HTTP_PROXY。
Dockerfile 顶部(FROM 之前或之后均可)写一下这个:
ARG HTTP_PROXY
ARG HTTPS_PROXY然后再将 ARG 的值传递到 ENV 变量(定义运行时环境变量,这些环境变量会保留在构建的镜像中,并在容器运行时生效)。
ENV HTTP_PROXY=${HTTP_PROXY}
ENV HTTPS_PROXY=${HTTPS_PROXY}扩展一下:如果你使用的是 docker-compose,可以在 docker-compose.yml 中这样设置:
version: '3'
services:
app:
image: your-image
environment:
- HTTP_PROXY=http://192.168.31.35:7890
- HTTPS_PROXY=http://192.168.31.35:7890
- NO_PROXY=localhost,127.0.0.1效果一样,见过就行了。
今天我们只需要构建的时候访问docker服务和apt服务器就行了,所以运行:
docker build \
--build-arg HTTP_PROXY=http://192.168.31.35:7890 \
--build-arg HTTPS_PROXY=http://192.168.31.35:7890 \
-t minikv-dev ./docker
7.5 运行Docker容器
进入容器并运行项目,我们的docker容器就是一个小虚拟机,里面的操作的debian一模一样。
docker run -it --rm -v $(pwd):/app -p 8080:8080 minikv-dev然后就是像本地一样编译运行了,也可以修改dockerfile在构建阶段编译好,都行的。
mkdir -p build && cd build
cmake ..
make
./minikv
# 记得输入2启动http模式如果这里报错大概率是Cmake的问题,build文件夹里面有之前编译的缓存,目录名字对不上,直接容器里面rm -rf build就可以了。
浏览器访问
我们的minikv 已内置 HTTP 服务(监听 0.0.0.0:8080),可直接通过浏览器访问:
http://localhost:8080/宿主机可以访问虚拟机的ip:8080。
http://192.168.31.234:8080/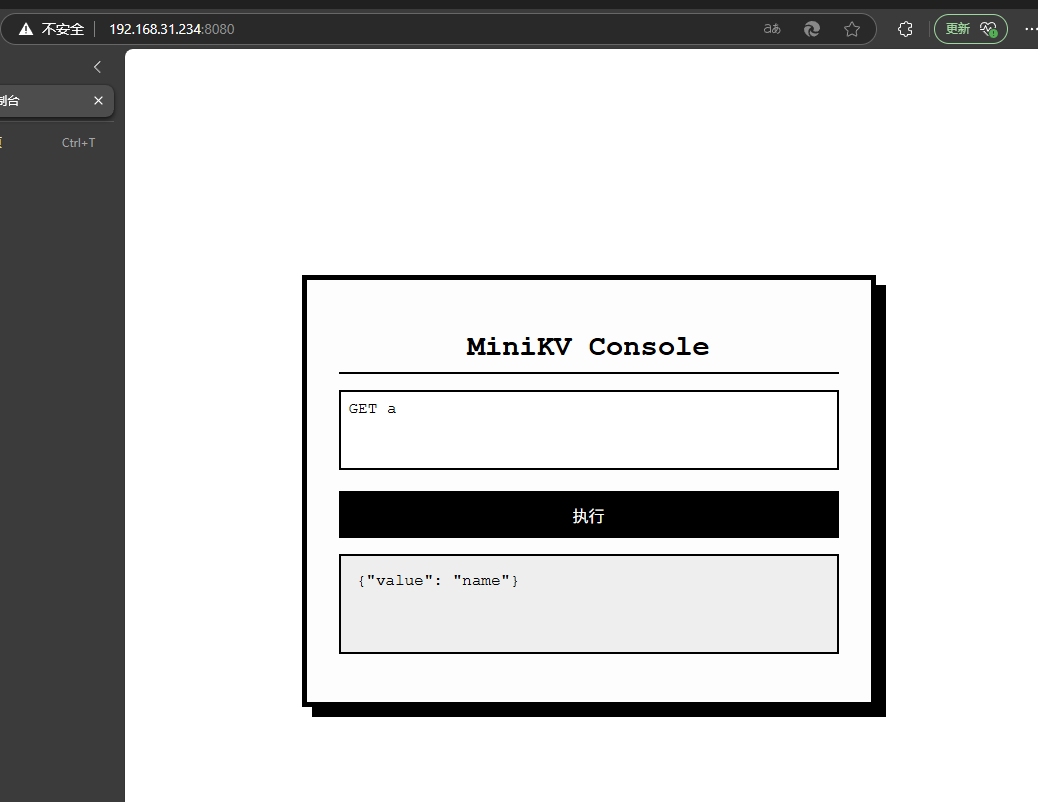
后记:开发的意义,是改变世界的能力
恭喜你,走到了 MiniKV Web 项目的终点,或者说另一个起点,接下来我们将会重写这个项目的底层,用更高级的语言,增加更多的能力。
现在,你已经亲手完成了一个从数据库内核、HTTP服务、API接口到前端页面的完整项目。你写过代码,调过 bug,测试过 API,构建过容器,也部署过服务——你已经真正体验了一次“开发者”的日常。
那么,现在回头看,我们来问一个问题:
什么是开发?
开发不仅是写代码
很多人一开始学编程,会把“开发”等同于“写代码”。但其实,写代码只是开发过程中的一环。真正的开发,更像是这样一件事:
你有一个想法,你用你的知识、工具和技术,把它变成一个真实可运行的系统。
比如:
- 你想做一个可以通过网页输入 SQL 的数据库;
- 你想让它在没有外部依赖的情况下独立运行;
- 你想在浏览器中输入
SELECT * FROM user;,它就能返回结果。
这些不是语法题,也不是标准答案,而是开放性问题。你得自己去思考如何设计模块、如何处理错误、如何写接口、如何优化内存。你在开发的每一步,都是在解决一个又一个真实的系统问题。
所以开发不是“刷题”,不是“写 demo”,而是构建系统、实现想法、解决问题。
你已经拥有了最基本的开发能力
通过这个项目,你已经掌握了几个核心能力:
- 理解系统结构:你知道了什么是 parser、engine、storage;什么是 API handler,什么是 HTTP 请求。
- 模块化思维:你学会了怎么拆分模块,每个模块该做什么,该如何交互。
- 调试与测试:你用 gdb 看过栈帧,用 Check 编写过单元测试——这些都是专业开发者日常用的工具。
- 部署与构建:你接触了 CMake 和 Docker,理解了软件如何从源码走向“可以运行”。
这些技能虽然基础,但已经能让你独立开发很多工具。更重要的是,你知道了自己可以做出东西。
从 MiniKV Web 出发,你可以走得更远
这个项目是一个起点,它可能无法直接解决现实世界中的所有问题,但它让你建立起了对“全局开发”的基本理解。
接下来,你可以:
- 替换数据库底层存储,引入文件系统或 B+ 树;
- 引入真正的 JSON 库,支持更复杂的响应结构;
- 将前端改为 React/Vue,做更好看的交互界面;
- 使用 curl 编写脚本,测试 API 的稳定性;
- 加入用户认证机制,实现权限管理。
你会发现,开发不是一门技能,而是一种创造力的表达方式。
只要你愿意深入思考、勇敢动手,每一次开发都是你在构建属于自己的小世界。
所以,感谢你跟我一起完成了 MiniKV Web。
愿你以此为起点,继续探索,继续构建,继续前行。愿你成为那个不仅会写代码,更能看见系统、理解逻辑、驾驭工具的开发者。
我们下一个项目再见。
—— 刚在田里摘完辣椒的DNG
附录:Git教程与规范
1. 基本概念
- 版本控制:版本控制是指对文件的修改历史进行记录和管理,使得每次更改都可以追溯和恢复。Git 是一种分布式版本控制系统,与集中式版本控制(如 SVN)相比,每个开发者都有一个完整的代码仓库副本,能更好地支持离线工作和协作。
- 仓库 (Repository):一个项目的存储库,包含了所有的文件、历史记录和提交信息。Git 仓库可以是本地的,也可以是远程的。
- 提交 (Commit):每次修改文件后的存档记录。每个提交都会有一个唯一的哈希值标识,可以查看这个提交的具体内容,甚至回到历史某个版本。
- 分支 (Branch):Git 允许你在同一仓库中创建多个分支。分支用于开发不同的功能或修复不同的问题,分支之间相互独立,可以独立地进行提交,不会影响主分支(通常是
main或master)。 - 合并 (Merge):将不同分支的内容合并到一起,通常是在完成某个功能开发后,合并回主分支。
- 远程仓库 (Remote Repository):存储在远程服务器上的仓库,多个开发者可以推送 (push) 和拉取 (pull) 代码,以便共享和同步工作进度。
2. 常用 Git 命令
-
git init:初始化一个新的 Git 仓库,创建
.git目录,用于跟踪项目中的文件变化。git init -
git clone <repo_url>:从远程仓库克隆一个 Git 仓库到本地。
git clone https://github.com/user/repo.git -
git status:查看工作区文件的当前状态,查看哪些文件被修改、哪些文件处于暂存区等。
git status -
git add :将文件添加到暂存区,准备提交。
git add filename -
git commit -m “message”:将暂存区的修改提交到本地仓库,并附上提交信息。
git commit -m "Fixed a bug in the login module" -
git log:查看提交历史,按时间顺序列出所有提交记录。
git log -
git diff:查看文件与版本库中上一个提交之间的差异。
git diff -
git pull:从远程仓库拉取最新的代码,并将其合并到当前分支。
git pull origin main -
git push:将本地仓库的提交推送到远程仓库。
git push origin main -
git branch:查看当前的分支。
git branch -
git checkout :切换到另一个分支。
git checkout feature-branch -
git merge :将某个分支的修改合并到当前分支。
git merge feature-branch
3. 分支管理与合并
在 Git 中,分支是一个非常重要的概念,它使得你能够在不干扰主分支的情况下进行独立的开发工作。通过分支,你可以在不同的开发任务之间切换,例如修复 bug、新功能开发、实验性开发等。
创建分支:
git branch new-feature切换分支:
git checkout new-feature创建并切换分支:
git checkout -b new-feature合并分支:
假设你在 feature-branch 分支上开发了一个新功能,现在你希望将其合并到 main 分支:
-
首先切换到
main分支:git checkout main -
然后合并
feature-branch分支:git merge feature-branch
解决冲突:
如果在合并过程中出现了冲突,Git 会提示冲突文件。此时,开发者需要手动编辑文件并解决冲突,解决后再执行:
git add <resolved-file>
git commit -m "Resolved merge conflict"4. Git 工作流
常见的 Git 工作流有:
- 集中式工作流:所有开发者都在
main或master分支上工作,常见于小团队或者单人开发。 - 功能分支工作流:每个功能或修复问题都在独立的分支上进行开发,开发完成后再合并回
main分支。这是团队协作中常见的工作流。 - Git Flow 工作流:Git Flow 是一种较为复杂的工作流,通常包括
master、develop、feature、release、hotfix等多个分支,适用于中大型团队。 - Fork-Branch 工作流:适用于开源项目,开发者从主仓库
fork一个副本,进行开发后通过 pull request 提交回主仓库。
5.Git初始配置:
设置作者信息
git config --global user.name "Your Name"
git config --global user.email [email protected]
设置默认分支名字
git config --global init.defaultBranch dev6.本次开发的分支策略
main(发布分支)
- 只保留稳定可运行的版本。
- 所有 release 均从此分支打 tag。
dev(开发主干,默认分支)
- 所有功能合并到此分支测试后再进入
main。 - 保持干净、有序的提交历史。
feature/*(功能开发分支)
- 每个模块/子功能单独开分支,开发完成后合并到
dev。
7.Git 提交模板
类型(范围): 简要说。/明
说明:
- 简要说明修改的动机和背景(可选)
变更内容:
- [ ] 简述修改点1
- [ ] 简述修改点2
备注:
- 关联问题:#编号
- 是否为破坏性变更:否示例提交
feat(auth): 新增 JWT 登录支持
说明:
- 实现用户登录后返回 JWT,替代原有 session 机制
- 整合认证流程,统一登录逻辑
变更内容:
- [x] 新增 jwt_middleware.go
- [x] 移除旧版 session 验证逻辑
备注:
- 关联问题:#42
- 是否为破坏性变更:是Git提交常用类型(type)
| 类型 | 说明 |
|---|---|
| add | 新增功能 |
| fix | 修复缺陷 |
| docs | 修改文档 |
| style | 格式调整(不影响功能) |
| refactor | 重构(无新增功能或修复) |
| perf | 性能优化 |
| test | 添加或修改测试 |
| chore | 构建配置、工具变动 |
| revert | 回滚提交 |
| release | 发布新版本 |
设置 Git 提交模板
- 保存模板文件(如
~/.gitmessage.zh):
cat > ~/.gitmessage.zh << 'EOF'
类型(范围): 简要说明
说明:
- 简要说明修改的动机和背景(可选)
变更内容:
- [ ]
备注:
- 关联问题:#Nil
- 是否为破坏性变更:No
EOF- 设置 Git 使用该模板:
git config --global commit.template ~/.gitmessage.zh3、使用方法
运行 git commit(不加 -m),Git 会打开编辑器并自动填入模板。你只需补充内容并保存即可。
8.我的Git 别名设置
直接编辑 ~/.gitconfig 文件
打开并编辑全局配置文件:
nano ~/.gitconfig添加或修改 [alias] 部分:
[alias]
st = status
co = checkout
cm = commit
br = branch
lg = log --oneline --graph --decorate --all
psh = push
pl = pull
last = log -1 HEAD
unstage = reset HEAD
alias = config --get-regexp alias
undo = reset --hard HEAD
l = log --oneline --graph --decorate
visual = log --oneline --graph --all --decorate --color
dc = diff --cached
ds = diff
acp = !f() { git add . && git commit -m \"$*\" && git push; }; f保存后即可使用。
我的这套涵盖了常用操作(分支、提交、日志、推送、撤销等)和增强型日志查看(lg、visual),适合入门新手使用。
| 别名 | 实际命令 | 功能说明 | 推荐级别 | 建议 |
|---|---|---|---|---|
st |
status |
查看当前仓库状态 | 推荐 | 无需修改 |
co |
checkout |
切换分支 | 推荐 | 可选添加 switch 用法 |
cm |
commit |
提交变更 | 推荐 | 可改为 ci 更常见 |
br |
branch |
查看/新建分支 | 推荐 | 无需修改 |
psh |
push |
推送变更 | 推荐 | 也可使用 pu 更短 |
pl |
pull |
拉取更新 | 推荐 | 无需修改 |
lg |
log --oneline --graph --decorate --all |
可视化 Git 历史图谱(推荐) | 推荐 | 无需修改 |
last |
log -1 HEAD |
查看最后一次提交 | 推荐 | 可重命名为 latest 更语义化 |
unstage |
reset HEAD |
取消 git add 的暂存操作 |
推荐 | 可配上参数提示更完整 |
alias |
config --get-regexp alias |
查看所有别名 | 推荐 | 可添加说明文档 |
undo |
reset --hard HEAD |
撤销当前工作区与暂存区(危险操作) | ⚠️ 有风险 | 添加确认提示更安全 |
l |
log --oneline --graph --decorate |
基本可视化历史(不含所有分支) | 推荐 | 和 lg 做功能区分 |
visual |
log --oneline --graph --all --decorate --color |
带颜色的完整日志图 | 推荐 | 视觉增强,无需修改 |
dc |
diff --cached |
查看暂存区的 diff | 推荐 | 可改为 dfc 更清晰 |
ds |
diff |
查看工作区的 diff | 推荐 | 无需修改 |
acp |
!f() { git add . && git commit -m $1 && git push; }; f |
一键添加、提交并推送 | ⚠️ 有限制 | 建议支持空格和输入交互 |
9.发布 Release 流程
- 切换到
main分支
git checkout main确保本地是最新的:
git pull origin main- 合并你要发布的变更(如果你是在 feature/dev 分支开发)
git merge dev
# 或者 git merge feature/xxx合并后可使用 git status 或 git diff 检查内容。
- 创建 Release 提交(可选,作为版本节点说明)
git commit -m "release: 发布 v1.2.0 版本,包含用户权限优化与API重构"如果无额外改动,可跳过。
- 打版本标签(Tag)
git tag -a v1.2.0 -m "发布 v1.2.0:优化性能,修复登录Bug"其中:
-a:创建附注标签(annotated tag,推荐)-m:标签说明,写清楚版本亮点
- 推送代码和标签
git push origin main # 推送主分支代码
git push origin v1.2.0 # 推送对应 tag你也可以一次性推送所有 tag:
git push origin --tags书籍版本:2025-05-07